


TL;DR
AU-Harness is a standardized, efficient and highly customizable open-source framework for evaluating audio-based language models on Audio-to-Text tasks. Built for researchers and developers, it provides a comprehensive suite of tools to benchmark and compare the performance of various audio processing models.
-
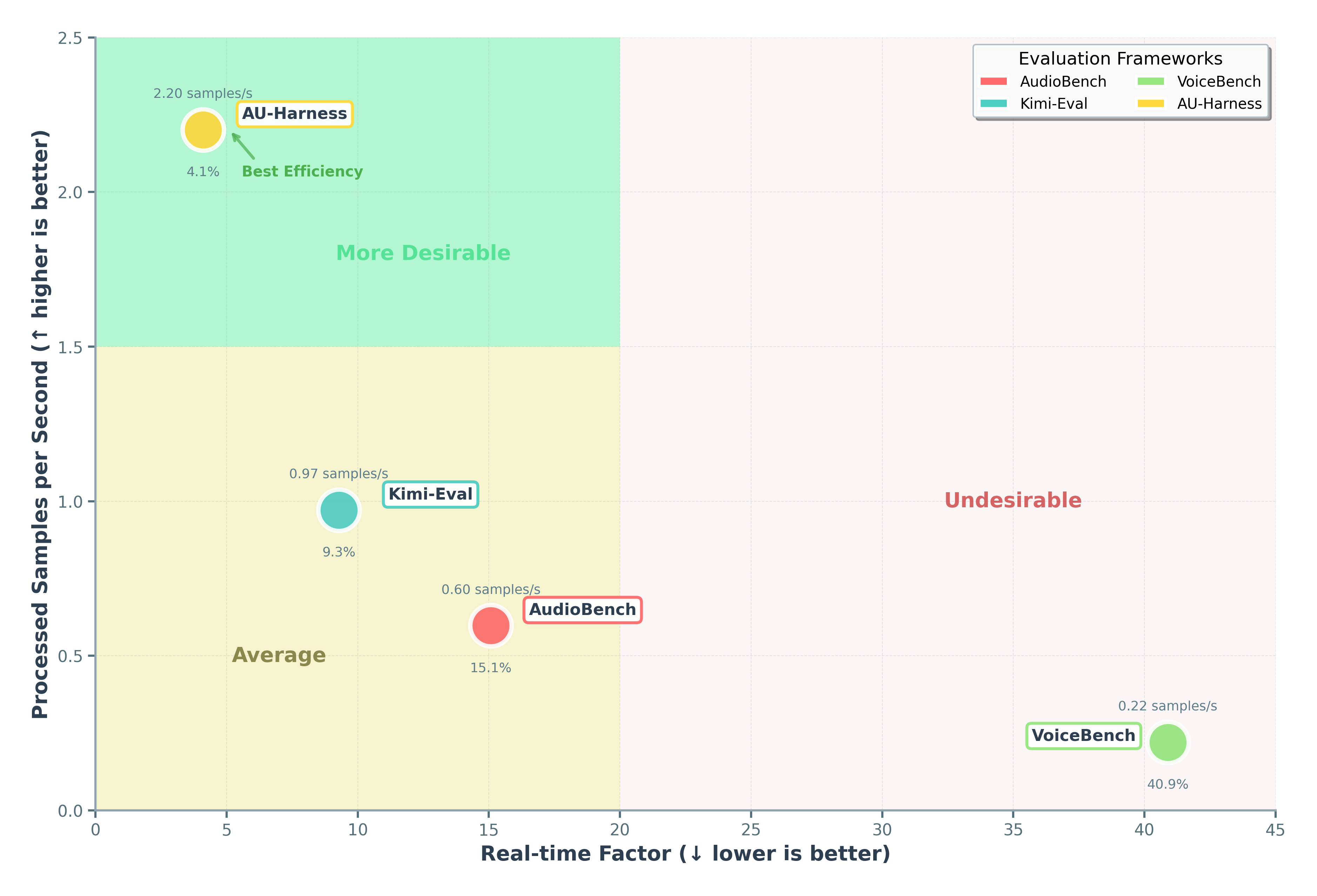
Blazing Fast — Multiple models evaluated simultaneously across multiple tasks, datasets and metrics using independent Engines, enabling full parallelization. Achieves a speedup of up to 127% over existing toolkits.
-
Immensely Customizable — Options to filter datasets by accents, language, length, and customize models, tasks, and score reporting.
-
Super Modular — Streamlined evaluation processes and modularized functions for easy extension.
-
Wide Task Coverage — Supporting 21 unique tasks across 6 categories, 50+ datasets with 380+ unique subsets, and 9 different metrics.
What is AU-Harness?
Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities.
To address these challenges, we present AU-Harness, a comprehensive evaluation framework that transforms how audio language models are benchmarked through three core contributions:
- High-Performance Evaluation Engine: Our architecture leverages vLLM batching, dataset sharding, and parallel task execution to scale evaluations to multi-node infrastructures without sacrificing fidelity.
- Unified Configuration System: Standardizes prompting, generation parameterization, metrics and reporting across benchmarks, enabling fair, reproducible comparisons and easy task integration.
- Expanded Reasoning Assessment: Introduces 3 new spoken language reasoning tasks for audio conditioned reasoning and an LLM-Adaptive Diarization task to assess temporal grounding.
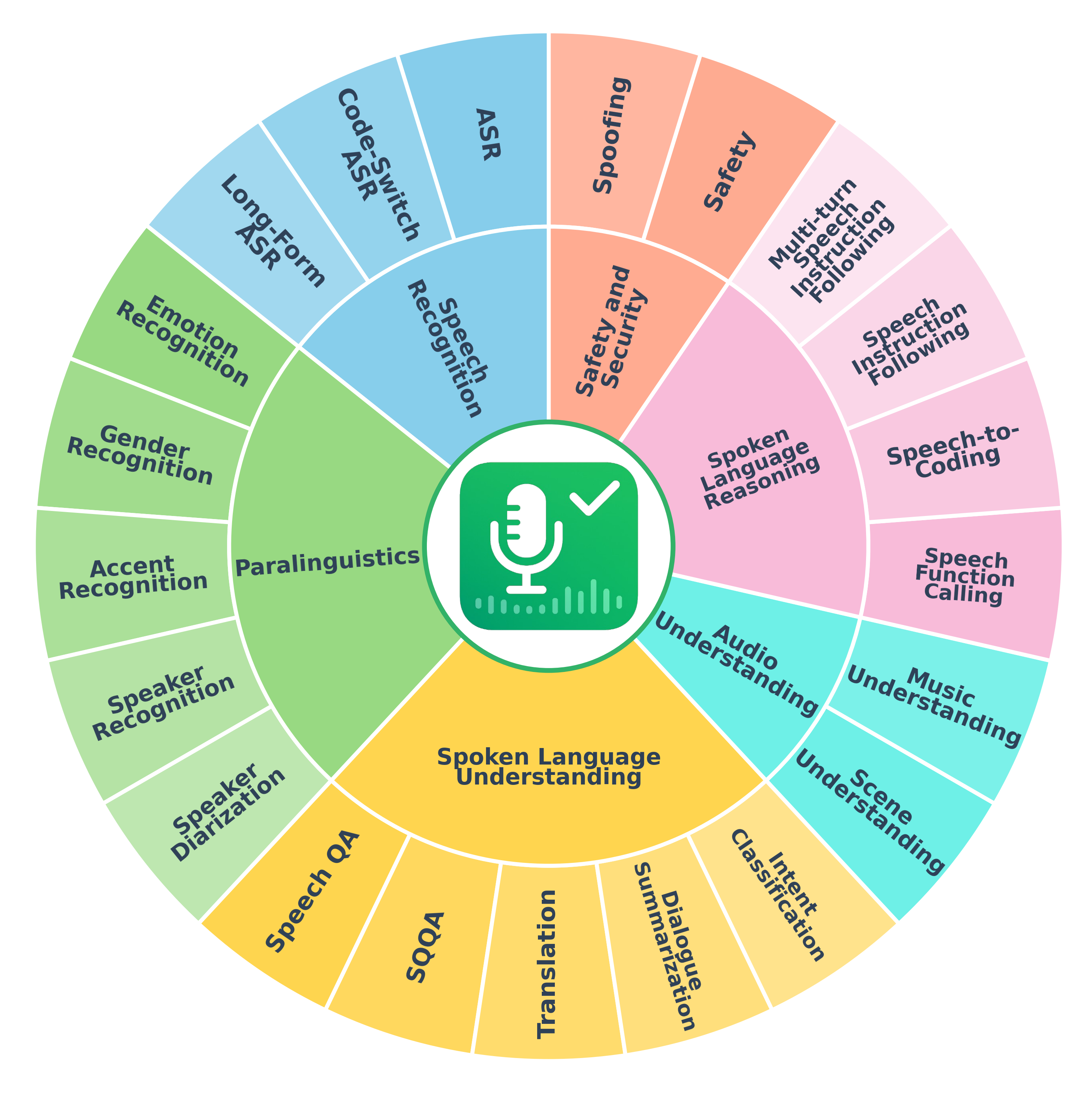
Task Taxonomy
Organization of 21 tasks across 6 categories
Leaderboard
| Model | Librispeech WER |
MELD llm_judge_binary |
IEMOCAP llm_judge_binary |
VoxCeleb llm_judge_binary |
mmau_mini llm_judge_binary |
CallHome WDER |
public_sg_speech_qa_test llm_judge_detailed |
BigBench Audio llm_judge_big_bench_audio |
Covost2 (zh-CN->EN) BLEU |
mnsc_sds (P3) llm_judge_detailed |
SLURP llm_judge_binary |
audiocaps_qa llm_judge_detailed |
mu_chomusic_test llm_judge_binary |
IFEval instruction_following_score |
MTBench llm_judge_mt_bench |
Spider sql_score (EM) |
BFCL bfcl_match_score |
advbench redteaming_judge |
avspoof llm_judge_binary |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voxtral-Mini-3B | 2.10 | 28.4 | 54.9 | 13.0 | 45.8 | 35.38 | 62.12 | 43.5 | 15.27 | 52.2 | 42.5 | 14.96 | 45.4 | 38.06 | 64.12 | 30.17 | 78.5 | 78.5 | 91.5 |
| Phi-4-multimodal-instruct | 1.97 | 30.5 | 50.5 | 27.6 | 47.2 | 39.31 | 63.32 | 40.8 | 24.32 | 54.8 | 23.0 | 26.08 | 44.8 | 49.74 | 58.0 | 27.37 | 17.1 | 97.1 | 10.0 |
| Qwen-2.5-Omni-7B | 1.74 | 49.8 | 85.8 | 28.7 | 62.3 | 35.4 | 69.4 | 53.8 | 28.41 | 52.0 | 57.0 | 38.4 | 59.3 | 50.83 | 62.88 | 38.46 | 68.0 | 98.3 | 30.0 |
| Ultravox-v0_6-llama-3_3-70b | 6.41 | 42.6 | 42.5 | 33.7 | 44.7 | 35.39 | 67.82 | 75.2 | 19.09 | 56.2 | 68.5 | 10.6 | 54.8 | 76.6 | 68.0 | 31.27 | 84.38 | 88.1 | 45.5 |
| GPT-4o-mini-audio-preview [WIP] | 6.25 | 20.2 | 0* | 0* | 42.0 | 37.14 | 70.2 | 65.0 | 21.68 | 61.2 | 48.0 | 15.08 | 50.2 | 72.15 | 62.44 | 45.15 | 86.65 | 88.1 | 0* |